Dans cette première partie je vais parler des données : d’où elles viennent, et comment elles sont transformées et analysées avant d’être utilisées dans Naonedbus.
L’origine des données
À ses débuts Naonedbus récupérait les horaires, la liste des lignes et arrêts, en lisant directement le site de la Tan, c’est à dire en parsant l’html. Bien évidemment à chaque fois que le site changeait Naonedbus ne fonctionnait plus.
Avec l’arrivée de l’Open Data tout a changé, la Tan fournit maintenant un fichier contenant toutes les informations nécessaires : le GTFS. Ce fichier est une simple archive contenant plusieurs fichiers textes au format CSV. Les principaux fichiers sont :
- routes.txt : La liste des lignes
- stops.txt : La liste des arrêts
- stop_times.txt : Les horaires aux arrêts
- trips.txt : Les trajets de chaque lignes
- calendar.txt : Les services (ici vert, jaune, bleu… pour la Tan)
Toutes les spécifications sont disponibles sur le repo Github google/transit
On a donc des lignes, des arrêts et des trajets. Plein de trajets. 42 908 dans le dernier GTFS de la Tan en date. Ils correspondent à un voyage d’un bus lors de sa tournée. Seul problème, tous ces trajets ne donnent pas une idée claire du trajet global du bus, de sa direction. Il n’y a plus qu’à la créer !
Transformation des données : Naomaker
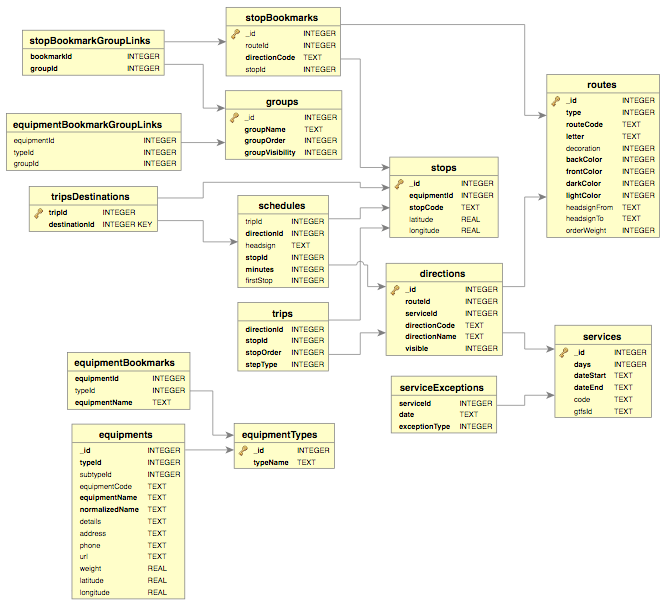
C’est ici qu’intervient Naomaker, un des projets de Naonedbus. Il a pour mission d’analyser le GTFS, de transformer certaines informations, les enrichir, et de générer une base de données.
Génération des directions
Le fichier clé du GTFS est sans aucun doute stop_times.txt, qui répertorie tous les trajets des véhicules, indiquant par quels arrêts ils passent et bien sûr à quelle heure ils s’y arrêtent. On a donc pour chaque ligne un ensemble de trajets, pas forcément identiques :

On voit ici les différents trajets de cette ligne : les véhicules font A → B → C → E → F mais aussi A → B → C → D.
Pour créer la direction correspondante, Naomaker va fusionner tous ces trajets afin d’avoir une représentation claire du trajet global :

Cette ligne s’arrête principalement en F, mais aussi de temps en temps en D. La représentation finale comporte bien cette notion de terminus multiples permettant à l’utilisateur de comprendre la ligne.
Il y a beaucoup de cas différents à gérer : le challenge technique est ici de concevoir un algorithme suffisamment souple pour s’adapter à toutes ces possibilités. Pour simplifier, je n’ai géré que les cas possibles dans le réseau Tan, comme par exemple de gauche à droite : les terminus multiples, les trajets alternatifs et les coupures.

Exemples de tracés dans Naonedbus
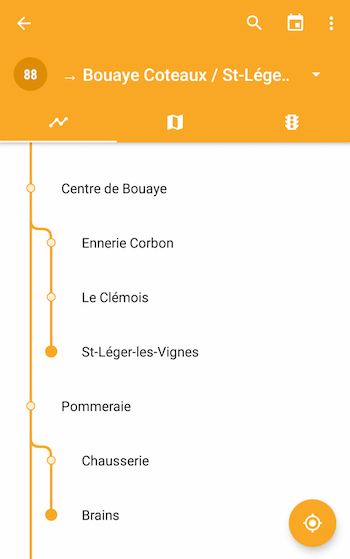
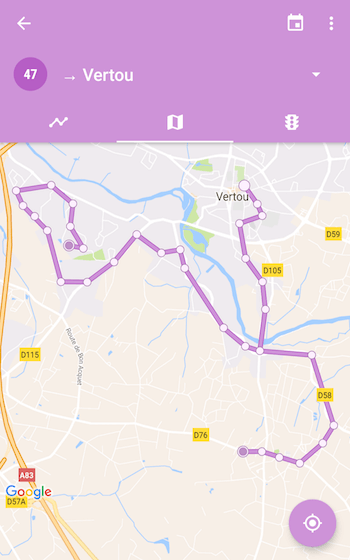
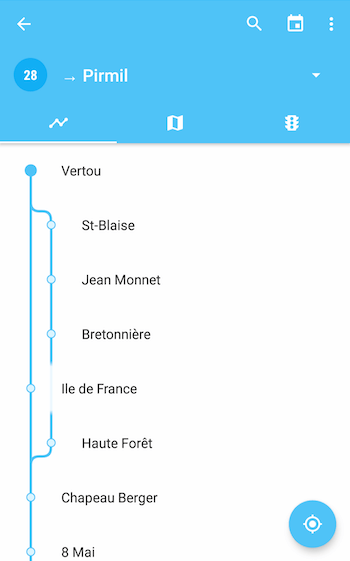
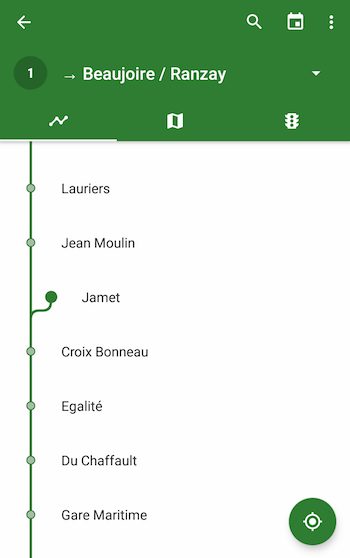
Limitations
Si mon algorithme fonctionne plutôt bien pour les lignes de la Tan, il n’est pas encore assez intelligent pour gérer tous les cas possibles. Je l’ai essayé sur d’autres GTFS, notament celui du Lila (transport régional) mais certaines lignes sont bien trop alambiquées.
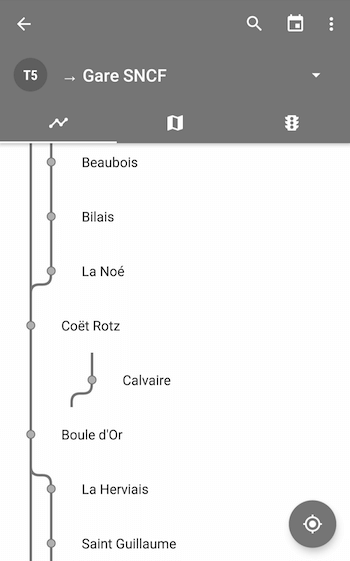
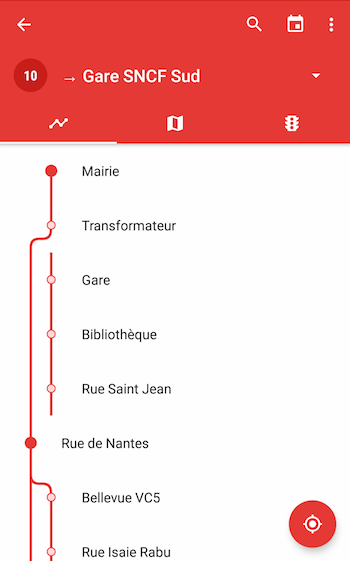
Ceci dit, il fonctionne correctement pour Rennes, Montréal ou encore Madrid… 😀
Compilation des horaires et services
Pour lire les horaires, c’est encore une fois le fichier stop_times.txt qui va nous intéresser : il répertorie tous les trajets, en indiquant les horaires de passage.
On a donc des trajets du genre :

On peut déduire la table horaire suivante :
| Arrêt | |||
|---|---|---|---|
| A | 8:00 | 8:16 | 8:32 |
| B | 8:08 | 8:32 | 8:40 |
| C | 8:12 | 8:36 | 8:44 |
| D | 8:19 | 8:42 | 8:50 |
| E | 8:23 | 8:54 | |
| F | 8:30 | 9:00 |
Facile ! Trop même. On oublie ici une chose : les services.
Jours verts, jours jaunes, jours bleus, on connaît tous le calendrier de la Tan qui indique la fréquence des bus et trams : il s’agit des services.
Dans le GTFS, ils sont renseignés dans le fichier calendar.txt. Ils comportent une date de début, de fin, et les jours de la semaine pour lesquels ils sont actifs. Pour compliquer un peu plus la chose, calendar_dates.txt vient ajouter des exceptions, pour supprimer ou ajouter ponctuellement un service à un jour donné (très utile pour les jours fériés par exemple).
La hiérachie d’information ressemble donc à :

Plutôt simple jusqu’ici. Un problème se pose quand il y a plusieurs services en même temps, ce qui est par exemple le cas pour les renforts du mercredi. On se retrouve avec plusieurs directions similaires, ce qui ne cause aucun problème technique mais qui est visuellement peu compréhensible : l’utilisateur croit à des doublons.
Naomaker va donc analyser les directions, et masquer celles qui sont des renforts : elles empruntent généralement le même tracé que la direction principale, ou juste une portion.

Une fois le GTFS analysé et enrichi, il ne reste plus qu’à construire la base de données.
Création de la base de données
À la place d’un fichier GTFS, l’appli Naonedbus fonctionne grâce à une base de données générée à partir de celui-ci. C’est plus performant, et la struture de données optimisée permet de gagner de la place : le dernier GTFS en date fait 86 Mo, la base de données générée ne fait que 49 Mo. Une base de données sans horaire de seulement 2 Mo est aussi générée (pour le mode “En ligne”).
49 Mo nécessaires pour contenir :
- 114 368 horaires
- 34 705 trajets [1]
- 3 564 arrêts
- 1 395 directions
- 101 lignes
- 94 services et 558 exceptions
[1] : Pourquoi pas 42 908 comme précisé plus haut ? Les services sont filtrés à la date de création de la base de données et ceux n’ayant plus cours sont supprimés, ainsi que leurs trajets.
Manipuler autant de données sur un smartphone implique d’optimiser chaque table, chaque requête, tout en ne créant que les index strictement nécessaires afin de garder une taille de fichier acceptable.
J’ai passé pas mal de temps à optimiser le modèle de données et les requêtes SQL pour réduire le temps d’exécution et la taille de fichier, tout en gardant Naonedbus assez rapide même sur des vieux smartphones.
Vérification des données : Naocal & Naochecker
Comme j’en parlais dans un post précédent, je vérifie les horaires pour m’assurer une certaine fiabilité. Cette vérification se fait en 2 étapes : la génération d’un calendrier et la vérification des horaires par rapport à l’API de la Tan
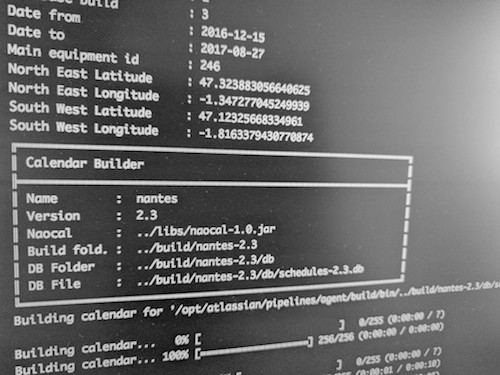
Génération d’un calendrier : Naocal
Le but ici est de pouvoir vérifier visuellement que les services du GTFS sont cohérents, qu’il n’y a pas eu d’oubli ou de conflit de service (un service jaune en même temps qu’un vert par exemple), ou encore que les jours fériés sont bien gérés comme tel.
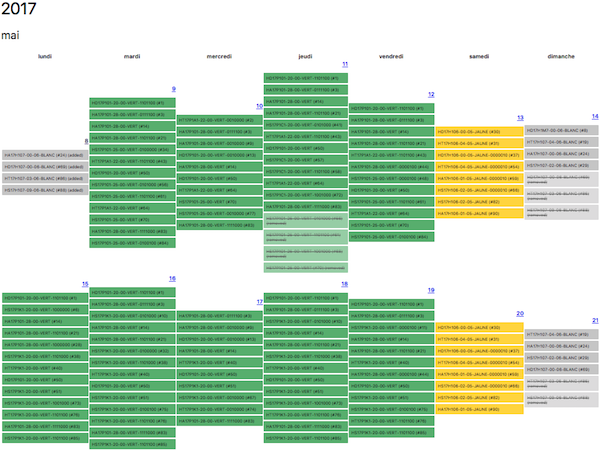

Les derniers calendriers générés sont disponibles à l’adresse calendar.naonedbus.net.
Vérification des horaires : Naochecker
La vérification des horaires se fait pour chaque lignes, chaque services, à la date de début et de fin de celui-ci. Naochecker va comparer les horaires du GTFS à ceux renvoyés par l’API de la Tan, et donner un indicateur de fiabilité pour chaque ligne. Plus de détails ici !
Automatisation : Naobash
Comme vous le voyez, beaucoup d’étapes sont nécessaires pour mettre à jour les données quand un nouveau GTFS est fourni par la Tan:
- Détecter la disponibilité d’un nouveau GTFS
- Télécharger le dernier GTFS
- Construire les base de données
- Construire le calendrier et lancer l’analyse des horaires
- Télécharger la dernière carte OpenStreetMap et la découper
- Construire le fichier necessaire à OpenTripPlanner, le calculateur d’itinéraires
- Déployer les fichiers construits sur le serveur de Naonedbus
Le projet Naobash vient automatiser tout ça. Il s’agit simplement d’un ensemble de 8 scripts Bash qui coordonne les programmes cités ci-avant, et effectue toutes ces étapes en seulement 5 minutes contre plusieurs heures de travail manuel auparavant 🙌
Le prochain article parlera de la partie serveur de Naonedbus : à quoi il sert et comment il fonctionne.
Merci à Benoît pour la relecture !